Home › Forum Online Discussion › Practice › How an AI trained to read scientific papers could predict future discoveries
- This topic has 1 reply, 1 voice, and was last updated 6 years ago by
c_howdy.
-
AuthorPosts
-
September 24, 2019 at 11:45 am #59322
c_howdy
ParticipantSEPTEMBER 24, 2019
https://techxplore.com/news/2019-09-ai-scientific-papers-future-discoveries.html
by Marcello Trovati
“Can machines think?”, asked the famous mathematician, code breaker and computer scientist Alan Turing almost 70 years ago. Today, some experts have no doubt that Artificial Intelligence (AI) will soon be able to develop the kind of general intelligence that humans have. But others argue that machines will never measure up. Although AI can already outperform humans on certain tasks—just like calculators—they can’t be taught human creativity.
After all, our ingenuity, which is sometimes driven by passion and intuition rather than logic and evidence, has enabled us to make spectacular discoveries—ranging from vaccines to fundamental particles. Surely an AI won’t ever be able to compete? Well, it turns out they might. A paper recently published in Nature reports that an AI has now managed to predict future scientific discoveries by simply extracting meaningful data from research publications.
Language has a deep connection with thinking, and it has shaped human societies, relationships and, ultimately, intelligence. Therefore, it is not surprising that the holy grail of AI research is the full understanding of human language in all its nuances. Natural Language Processing (NLP), which is part of a much larger umbrella called machine learning, aims to assess, extract and evaluate information from textual data.
Children learn by interacting with the surrounding world via trial and error. Learning how to ride a bicycle often involves a few bumps and falls. In other words, we make mistakes and we learn from them. This is precisely the way machine learning operates, sometimes with some extra “educational” input (supervised machine learning).
For example, an AI can learn to recognise objects in images by building up a picture of an object from many individual examples. Here, a human must show it images containing the object or not. The computer then makes a guess as to whether it does, and adjusts its statistical model according to the accuracy of the guess, as judged by the human. However we can also leave the computer program to do all the relevant learning by itself (unsupervised machine learning). Here, AI automatically starts being able to detect patterns in data. In either case, a computer program needs to find a solution by evaluating how wrong it is, and then try to adjust it to minimise such error.
Suppose we want to understand some properties related to a specific material. The obvious step is to search for information from books, web pages and any other appropriate resources. However, this is time consuming, as it may involve hours of web searching, reading articles and specialised literature. NLP can, however, help us. Via sophisticated methods and techniques, computer programs can identify concepts, mutual relationships, general topics and specific properties from large textual datasets.
In the new study, an AI learned to retrieve information from scientific literature via unsupervised learning. This has remarkable implications. So far, most of the existing automated NLP-based methods are supervised, requiring input from humans. Despite being an improvement compared to a purely manual approach, this is still a labour intensive job.
However, in the new study, the researchers created a system that could accurately identify and extract information independently. It used sophisticated techniques based on statistical and geometrical properties of data to identify chemical names, concepts and structures. This was based on about 1.5m abstracts of scientific papers on material science.
A machine learning program then classified words in the data based on specific features such as “elements”, “energetics” and “binders”. For example, “heat” was classified as part of “energetics”, and “gas” as “elements”. This helped connect certain compounds with types of magnetism and similarity with other materials among other things, providing an insight on how the words were connected with no human intervention required.
This method could capture complex relationships and identify different layers of information, which would be virtually impossible to carry out by humans. It provided insights well in advance compared to what scientists can predict at the moment. In fact, the AI could recommend materials for functional applications several years before their actual discovery. There were five such predictions, all based on papers published before the year 2009. For example, the AI managed to identify a substance known as CsAgGa2Se4as as a thermoelectric material, which scientists only discovered in 2012. So if the AI had been around in 2009, it could have speeded up the discovery.
It made the prediction by connecting the compound with words such as “chalcogenide” (material containing “chalcogen elements” such as sulfur or selenium), “optoelectronic” (electronic devices that source, detect and control light) and “photovoltaic applications”. Many thermoelectric materials share such properties, and the AI was quick to show that.
This suggests that latent knowledge regarding future discoveries is to a large extent embedded in past publications. AI systems are becoming more and more independent. And there is nothing to fear. They can help us enormously to navigate through the huge amount of data and information, which is being continuously created by human activities. Despite concerns related to privacy and security, AI is changing our societies. I believe it will lead us to make better decisions, improve our daily lives and ultimately make us smarter.
 February 13, 2020 at 2:27 am #59707Participant
February 13, 2020 at 2:27 am #59707Participant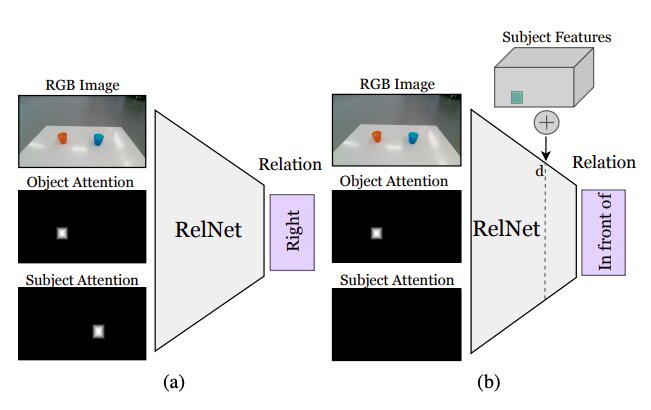
Figure summarizing how the approach devised by the researchers works. An auxiliary CNN, called RelNet, is trained to predict spatial relations given the input image and two attention masks referring to two objects forming a relation. (a) after training, the network can be ‘tricked’ to classify hallucinated scenes by (b) implementing high-level features of items at different spatial locations. Credit: Mees et al.
Training robots to identify object placements by ‘hallucinating’ scenes
FEBRUARY 12, 2020
by Ingrid Fadelli , Tech Xplore
https://techxplore.com/news/2020-02-robots-placements-hallucinating-scenes.html
With more robots now making their way into a number of settings, researchers are trying to make their interactions with humans as smooth and natural as possible. Training robots to respond immediately to spoken instructions, such as “pick up the glass, move it to the right,” etc., would be ideal in many situations, as it would ultimately enable more direct and intuitive human-robot interactions. However, this is not always easy, as it requires the robot to understand a user’s instructions, but also to know how to move objects in accordance with specific spatial relations.
Researchers at the University of Freiburg in Germany have recently devised a new approach for teaching robots how to move objects around as instructed by human users, which works by classifying “hallucinated” scene representations. Their paper, pre-published on arXiv, will be presented at the IEEE International Conference on Robotics and Automation (ICRA) in Paris, this June.
“In our work, we concentrate on relational object placing instructions, such as ‘place the mug on the right of the box’ or ‘put the yellow toy on top of the box,'” Oier Mees, one of the researchers who carried out the study, told TechXplore. “To do so, the robot needs to reason about where to place the mug relative to the box or any other reference object in order to reproduce the spatial relation described by a user.”
Training robots to make sense of spatial relations and move objects accordingly can be very difficult, as a user’s instructions do not typically delineate a specific location within a larger scene observed by the robot. In other words, if a human user says “place the mug on the left of the watch,” how far left from the watch should the robot place the mug and where is the exact boundary between different directions (e.g., right, left, in front of, behind, etc.)?
“Due to this inherent ambiguity, there is also no ground-truth or ‘correct’ data that can be used to learn to model spatial relations,” Mees said. “We address the problem of the unavailability of ground-truth pixelwise annotations of spatial relations from the perspective of auxiliary learning.”
The main idea behind the approach devised by Mees and his colleagues is that when given two objects and an image representing the context in which they are found, it is easier to determine the spatial relationship between them. This allows the robots to detect whether one object is to the left of the other, on top of it, in front of it, etc.
While identifying a spatial relationship between two objects does not specify where the objects should be place to reproduce that relation, inserting other objects within the scene could allow the robot to infer a distribution over several spatial relations. Adding these nonexistent (i.e., hallucinated) objects to what the robot is seeing should allow it to evaluate how the scene would look if it performed a given action (i.e., placing one of the objects in a specific location on the table or surface in front of it).
“Most commonly, ‘pasting’ objects realistically in an image requires either access to 3-D models and silhouettes or carefully designing the optimization procedure of generative adversarial networks (GANs),” Mees said. “Moreover, naively “pasting” object masks in images creates subtle pixel artifacts that lead to noticeably different features and to the training erroneously focusing on these discrepancies. We take a different approach and implant high-level features of objects into feature maps of the scene generated by a convolutional neural network to hallucinate scene representations, which are then classified as an auxiliary task to get the learning signal.”
Before training a convolutional neural network (CNN) to learn spatial relations based on hallucinated objects, the researchers had to ensure that it was capable of classifying relations between individual pairs of object based on a single image. Subsequently, they “tricked” their network, dubbed RelNet, into classifying “hallucinated” scenes by implanting high-level features of items at different spatial locations.
“Our approach allows a robot to follow natural-language placing instructions given by human users with minimal data collection or heuristics,” Mees said. “Everybody would like to have a service robot at home which can perform tasks by understanding natural-language instructions. This is a first step to enable a robot to better understand the meaning of commonly used spatial prepositions.”
Most existing method for training robots to move objects around use information related to the objects” 3-D shapes to model pairwise spatial relationships. A key limitation of these techniques is that they often require additional technological components, such as tracking systems that can trace the movements of different objects. The approach proposed by Mees and his colleagues, on the other hand, does not require any additional tools, since it is not based on 3-D vision techniques.
The researchers evaluated their method in a series of experiments involving real human users and robots. The results of these tests were highly promising, as their method allowed robots to effectively identify the best strategies to place objects on a table in accordance with the spatial relations outlined by a human user’s spoken instructions.
“Our novel approach of hallucinating scene representations can also have multiple applications in the robotics and computer vision communities, as often robots often need to be able to estimate how good a future state might be in order to reason over the actions they need to take,” Mees said. “It could also be used to improve the performance of many neural networks, such as object detection networks, by using hallucinated scene representations as a form of data augmentation.”
Mees and his colleagues we able to model a set of natural language spatial prepositions (e.g. right, left, on top of, etc.) reliably and without using 3-D vision tools. In the future, the approach presented in their study could be used to enhance the capabilities of existing robots, allowing them to complete simple object shifting tasks more effectively while following a human user’s spoken instructions.
Meanwhile, their paper could inform the development of similar techniques to enhance interactions between humans and robots during other object manipulation tasks. If coupled with auxiliary learning methods, the approach developed by Mees and his colleagues may also reduce the costs and efforts associated with compiling datasets for robotics research, as it enables the prediction of pixelwise probabilities without requiring large annotated datasets.
“We feel that this is a promising first step towards enabling a shared understanding between humans and robots,” Mees concluded. “In the future, we want to extend our approach to incorporate an understanding of referring expressions, in order to develop a pick-and-place system that follows natural language instructions.”
More information: Learning object placements for relational instructions by hallucinating scene representations. arXiv:2001.08481 [cs.RO].

-
AuthorPosts
- You must be logged in to reply to this topic.